
本文档链接 https://blog.csdn.net/weixin_42487906/article/details/115437890
RISCV向量指令集学习
参考链接
https://github.com/riscv/riscv-v-spec
RSIC-V——指令集spec阅读笔记——向量扩展0.9
RISC-V Vector Extension学习笔记
向量指令集用例
可以对照下面的说明来看这个例子
1 | .text |
名词解释
| ELEN | 向量中单个元素的最大长度,bit为单位,要求ELEN>=8,且为2的幂 |
| VLEN | 向量寄存器的位数,bit为单位,要求VLEN ≥ ELEN,并且必须是2的幂 |
| SLEN | 分段距离(The striping distance in bits),要求必须为VLEN ≥ SLEN ≥ 32,并且必须为2的幂,这个暂时没懂 |
| SEW | 标准元素宽度,以bit为单位,指向量中一个元素占向量寄存器中的位数 |
| LMUL | 向量寄存器分组数 |
| 寄存器定义 | |
| v0-v31 | 向量数据寄存器,共32个,固定位宽为VLEN位 |
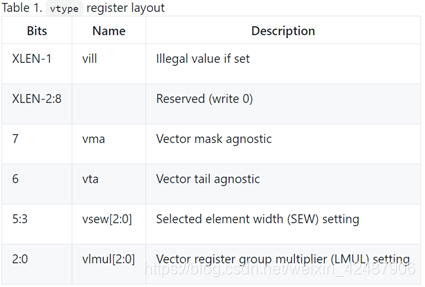
| vtype | 向量数据类型寄存器,并且只能通过vsetvl{i}指令进行更新,向量类型还决定了每个向量寄存器中元素的排布,以及如何对多个向量寄存器进行分组。 |
| vsew[2:0] | 变化的标准元素宽度(SEW, standard element width)值通过vsew中的值设置。默认情况下,向量寄存器被视为分成 VLEN / SEW 个标准宽度元素。 |
| vlmul[2:0 ] | 向量寄存器分组,分成一组的多个向量寄存器可以当作一个操作数来用,用来存放一个向量,该值也可以是小数,用来等效增加向量数据寄存器的数量 |
| VLMAX | VLMAX = LMUL * VLEN / SEW, |
| vta和vma | 这两位元素值在执行向量指令期间分别修改了目标尾部元素(Tail Elements)和非活跃的掩码元素(Inactive masked-off Elements)的行为。 |
| vill | vill位用于编码先前的vsetvl{i} 指令试图向vtype写入不支持的值 |
| vl | 向量长度寄存器,以存放向量总共有多少个元素,只能通过vsetvli和vsetvl指令进行更新。 |
| vlen | 向量寄存器长度寄存器,是一个常数,保存值 VLEN / 8,即向量寄存器长度(以字节为单位)。 |
| vstart | vstart是一个可读可写的CSR寄存器,指定向量指令要执行的第一个元素的索引。每个向量指令执行完后,该寄存器清零。 |
| vcsr | 向量控制和状态寄存器vcsr,保存定点舍入的方式和饱和状态 |
 |
|
 |
向量元素到向量寄存器的映射
根据当前的 SEW 和 LMUL 设置以及 ELEN,VLEN 和 SLEN 的值,怎么将不同宽度的元素存放到矢量寄存器的字节中。并且使用最少位数的最低有效字节将元素放到每个向量寄存器中。
当 VLEN=SLEN , LMUL=1 时,从向量寄存器的最低有效位到最高有效位依次对元素进行简单排布。当 LMUL <1 时,仅使用向量寄存器中的第一个 LMUL * VLEN / SEW 元素。 向量寄存器中的剩余空间被视为尾部的一部分。


VLEN = SLEN 且 LMUL > 1时, 将向量寄存器分组后,根据向量寄存器组中的向量寄存器来划分组中的元素。当 SLEN = VLEN 时,按元素顺序将其放在组中的每个向量寄存器中,填满一个向量寄存器后,便移至组中下一个编号最高的向量寄存器。
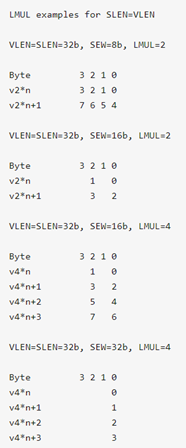

向量 ISA 的设计目的是支持混合宽度操作,并且不需要大量显式的额外的重排指令,也不需要大量额外的数据路径(datapath)布线。在对不同精度值的向量进行操作时,推荐的做法是动态修改 vtype 值,从而使得 SEW/LMUL 为常量(因此 VLMAX 常量)。向量寄存器分组因子(LMUL)按相关元素大小增加,这样每个向量寄存器组可以保存相同数量的向量元素(本例中 VLMAX=16 ),从而简化 stripmining 代码。下表列出了执行混合宽度操作的循环的每个可能的 SEW / LMUL 操作点。 每列代表一个恒定的 SEW / LMUL 操作点。 表中列出的内容是 LMUL 值,该值生成该列的 SEW / LMUL 值。 在同一列中, LMUL 的值不同,但 VLMAX 值相同。(可以保证每个向量寄存器组中的向量元素数量相同)

配置寄存器操作指令
vsetvli/vsetvl
用例
1 | vsetvli rd, rs1, vtypei |

解释
指令根据其参数设置 vtype 和 vl CSRs,并将 vl 的新值写入 rd。
两个指令的区别:vtypei是个立即数,rs2是个寄存器
AVL=应用程序向量长度
vsetvl{i}指令首先根据 vtype 参数,设定 VLMAX ,然后设置vl服从以下约束:
- 如果 AVL ≤ VLMAX ,则 vl = AVL
- 如果 AVL < (2 * VLMAX),则ceil(AVL / 2) ≤ vl ≤ VLMAX
- 如果 AVL ≥ (2 * VLMAX),则 vl = VLMAX
- 如果输入相同的 AVL 和 VLMAX 值,则任何实现中,v1 都是确定的
满足之前提及的规则:
如果 AVL = 0,则 vl = 0
如果 AVL > 0,vl > 0
vl ≤ VLMAX
vl ≤ AVL
从 vl 中读取的值(用作 vsetvl{i} 的 AVL 参数时)会在 vl 中产生相同的值,前提是所得的 VLMAX 等于读取vl时的 VLMAX 值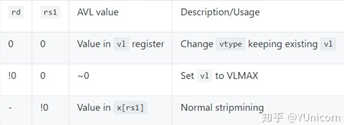

向量操作指令中的掩码
掩码vm
在指令中占一位,使用v0寄存器存放掩码值,vm为1时不启动掩码,vm为0时,当v0的相应位为1,目标向量寄存器写入相应的值
掩码向量的加载操作不会更新目标向量寄存器组中的非活跃元素。掩码向量的存储操作只更新内存中的活跃元素。
向量加载和存储指令(访存)

mop 访存时选择访存模式

支持连续访存,跨步访存和按索引访存
lumop/sumop
还没搞懂是做什么用的 fault only first似乎可以简化循环操作
向量加载/存储的宽度编码
- Mem bits(内存位)是内存中访问的每个元素的大小。
- Reg bits(寄存器位)是寄存器中访问的每个元素的大小。

向量单步幅跨步(Unit-Stride)指令
1 |
|
l代表load,e32代表向量元素长32
1 | #vs3 store data, rs1 base address, vm is mask encoding (v0.t or <missing>) |
s代表save
向量跨步(Strided)指令
1 |
|
vls中l代表load,s代表stride,rs2存放跨步值
1 | # vs3 store data, rs1 base address, rs2 byte stride |
vsse128中,第一个s是save,第二个是stride
向量索引(indexed)指令
1 |
|
有序加载,vs2存放索引,vs2中元素大小为16bit
1 | # Vector unordered-indexed store instructions |
无序存储,vs2中元素大小为64bit
向量原子操作
原子操作指令 暂时用不到
向量计算指令
向量的算术指令使用与 OP-FP 相邻的新的主要操作码1010111。 funct3 字段的三位用于定义向量指令的子类。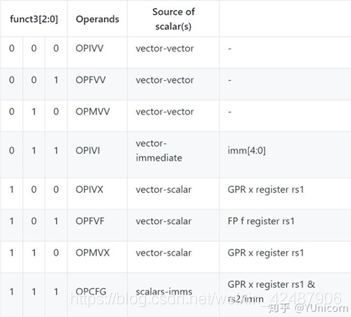
向量与标量之间的运算可以采取三种可能的形式,但无论采取哪种形式,都要从 vs2 指定的向量寄存器组中获取一个操作数向量,并从三个替代源之一获取第二个标量源操作数。
- 对于整数运算,标量可以是编码在 rs1 字段中5位立即数。该值通过符号扩展或加零扩展到SEW 位。
- 对于整数运算,可以从rs1 指定的标量寄存器x中提取标量。如果 XLEN > SEW,则使用x的最低有效SEW位。如果 XLEN < SEW,则x 寄存器的值通过符号扩展到 SEW 位。
- 对于浮点运算,可以从标量寄存器f中获取标量。如果 FLEN> SEW,则检查f寄存器中的值是否为有效的 NaN-boxed 值,如果是,则使用f寄存器的最低有效SEW位,否则将使用规范的 NaN 值。如果执行向量指令时,任何浮点向量操作数的 EEW 都不是支持的浮点类型宽度(包括 FLEN <SEW 时),则会引发非法指令异常。
向量算术指令在vm 字段下被掩码。
1 | # Operations returning vector results, masked by vm (v0.t, <nothing>) |
浮点指令
1 | vfop.vv vd, vs2, vs1, vm # FP vector-vector operation vd[i] = vs2[i] fop vs1[i] |
不同的指令格式
1 | # Integer operations overwriting sum input |
从指令上看没有什么区别,怎么区分二者呢
通过vop的不同来区分
Widening向量算术指令
一些矢量算术指令被定义为加宽(widening) 操作,其中 EEW = 2 * SEW ,EMUL = 2 * LMUL。
第一个操作数可以是单宽度或双宽度。这些通常在操作码上具有前缀 vw,或对于矢量浮点运算具有前缀 vfw。
1 | # Double-width result, two single-width sources: 2*SEW = SEW op SEW |
结果为双宽度,两个源操作数均为单宽度
1 | # Double-width result, first source double-width, second source single-width: 2*SEW = 2*SEW op SEW |
结果为双宽度,源操作数1为双宽度,源操作数2为单宽度
Narrowing向量算术指令
和加宽指令类似
这些指令将 EEW/EMUL = 2 * SEW / 2 * LMUL 的向量寄存器组转换为具有当前 LMUL/SEW 向量/元素的向量寄存器组。
如果 EEW> ELEN 或 EMUL> 8,则会引发非法指令异常。
向量单宽度加减
1 | # Integer adds. |
向量结果加宽加减,包括有符号数和无符号数
1 | # Widening unsigned integer add/subtract, 2*SEW = SEW +/- SEW |
向量有,无符号数元素位数扩展
1 | vzext.vf2 vd, vs2, vm # Zero-extend SEW/2 source to SEW destination |
带进位借位加减法
1 | # Produce sum with carry. |
位逻辑指令
1 | # Bitwise logical operations. |
单宽度位移指令,逻辑左移,逻辑和算数右移
1 | # Bit shift operations |
向量比较指令,符号左右两边分别是vs2和vs1
1 | # Set if equal |
向量找最大最小指令,最大/小结果放入vd中
1 | # Unsigned minimum |
向量单宽度整数乘法指令
1 | # Signed multiply, returning low bits of product |
向量单宽度整数除法及求余数指令
1 | # Unsigned divide. |
向量结果双宽度整数乘法指令
1 | # Widening signed-integer multiply |
向量单宽度整数乘加指令
1 | # Integer multiply-add, overwrite addend |
向量加宽整数乘加指令
1 | # Widening unsigned-integer multiply-add, overwrite addend |
向量整数合并指令
1 | vmerge.vvm vd, vs2, vs1, v0 |
向量整数移动指令
1 | vmv.v.v vd, vs1 |
整数标量移动指令
整数标量读/写指令在标量x寄存器和向量寄存器的元素0之间传输单个值。指令忽略LMUL和向量寄存器组。
1 | vmv.xs rd,vs2#x [rd] = vs2 [0](vs1 = 0) |
需求分析
- 向量的加载和存储,支持跨步,按索引范存(访存操作
- 向量单个元素位宽可指定(8bit,32bit)/可能支持向量寄存器分组
- 向量之间/向量和常数的加减乘除运算
- 向量之间/向量和常数的比较运算
- 向量自身所有元素求和
- 向量元素的位逻辑运算
- 求向量中,向量元素的最大最小值
RISCV指令格式


- 给用户自定义的指令操作码为Custom-0, Custom-1, Custom-2, Custom-3
1 | wire opcode_custom0 = (opcode == 7'b0001011); |
- 操作码如上,操作码定义为Custom-0, Custom-1, Custom-2, Custom-3,其余部分可仿照向量指令集,指令集主要由func3和func7区分
- 根据NICE示例代码可知,指令格式可为任意种类指令格式,但是文档中给出,指令格式仅使用R格式指令
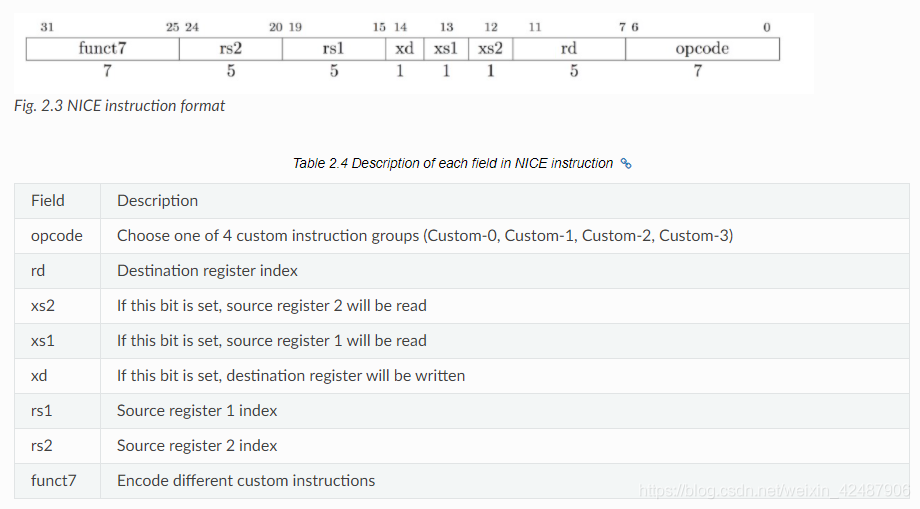
指令预设
访存指令
向量的加载和存储,支持跨步,按索引范存(访存操作
占用一个custom操作数,custom1
- 5bit保存要加载/存储的内存地址的寄存器编号
- 5bit保存若跨步访存的步长所在的寄存器编号/或按索引访存所存放索引的向量寄存器地址
- 5bit保存要存或取数据的向量寄存器的编号
- 2bit编码向量元素宽度
- 2bit编码采用连续访存还是跨步访存还是索引范存
- 1bit编码读操作还是写操作
按上述要求,采用R指令,1.2.3分给rs1,rs2,rs3,456分给func7
3.4.5.6.
也可采用R型指令,可分给custom2.3.4,具体指令类型由fun7指定(待定
NICE接口学习
NICE接口官方给出了较详细的文档说明
芯来官方资料汇总 https://www.rvmcu.com/community-topic-id-340.html
官方文档说明 https://doc.nucleisys.com/hbirdv2/core/core.html#nice
nice协处理器实现示例 https://github.com/riscv-mcu/e203_hbirdv2/tree/master/rtl/e203/subsys
协处理器使用示例 https://github.com/Nuclei-Software/nuclei-board-labs/tree/master/e203_hbirdv2/common